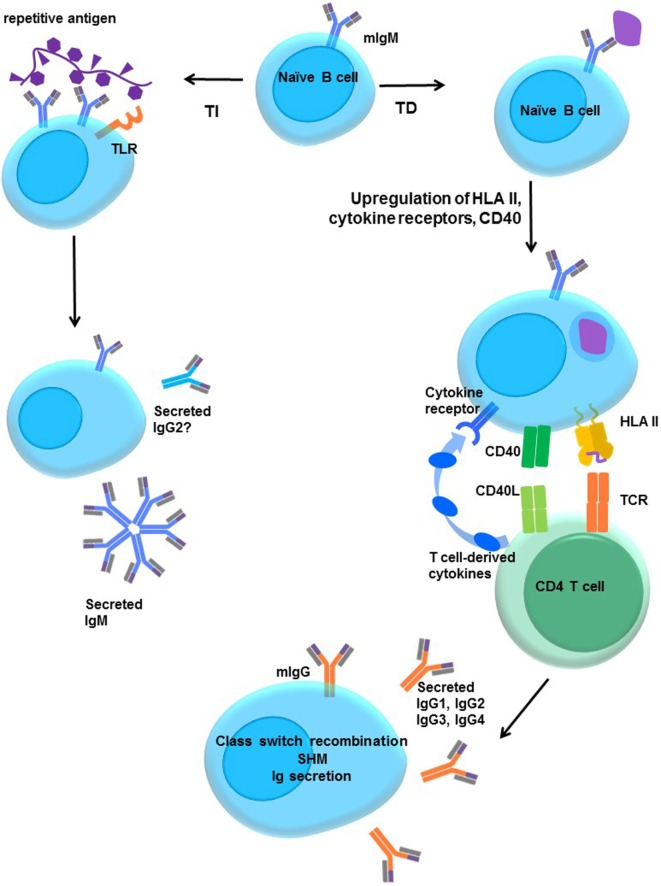
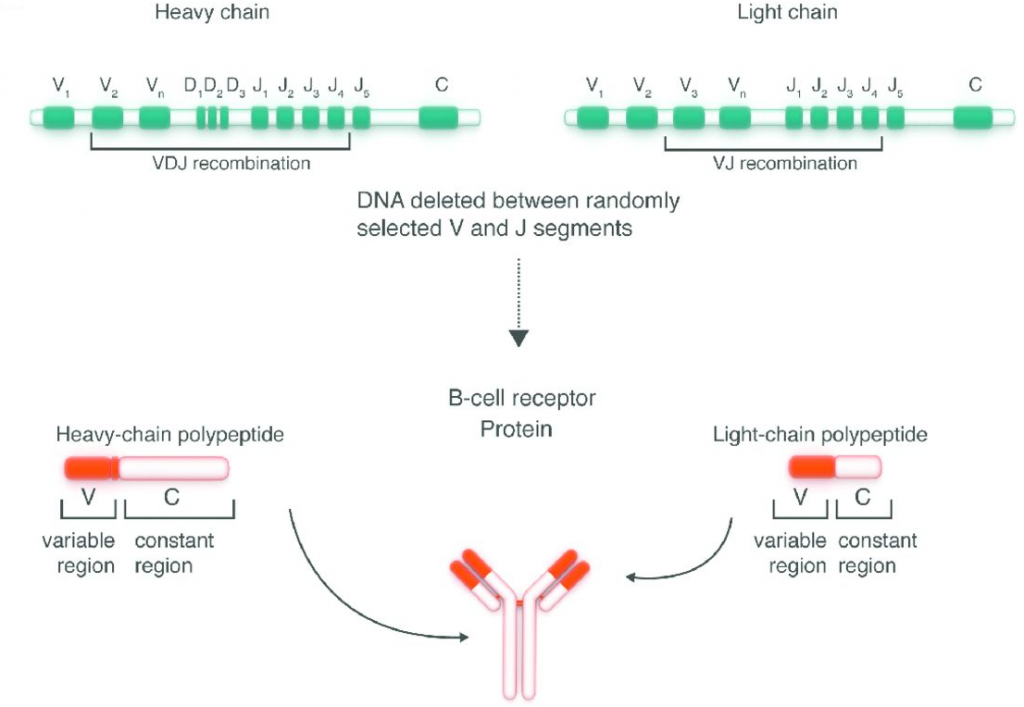

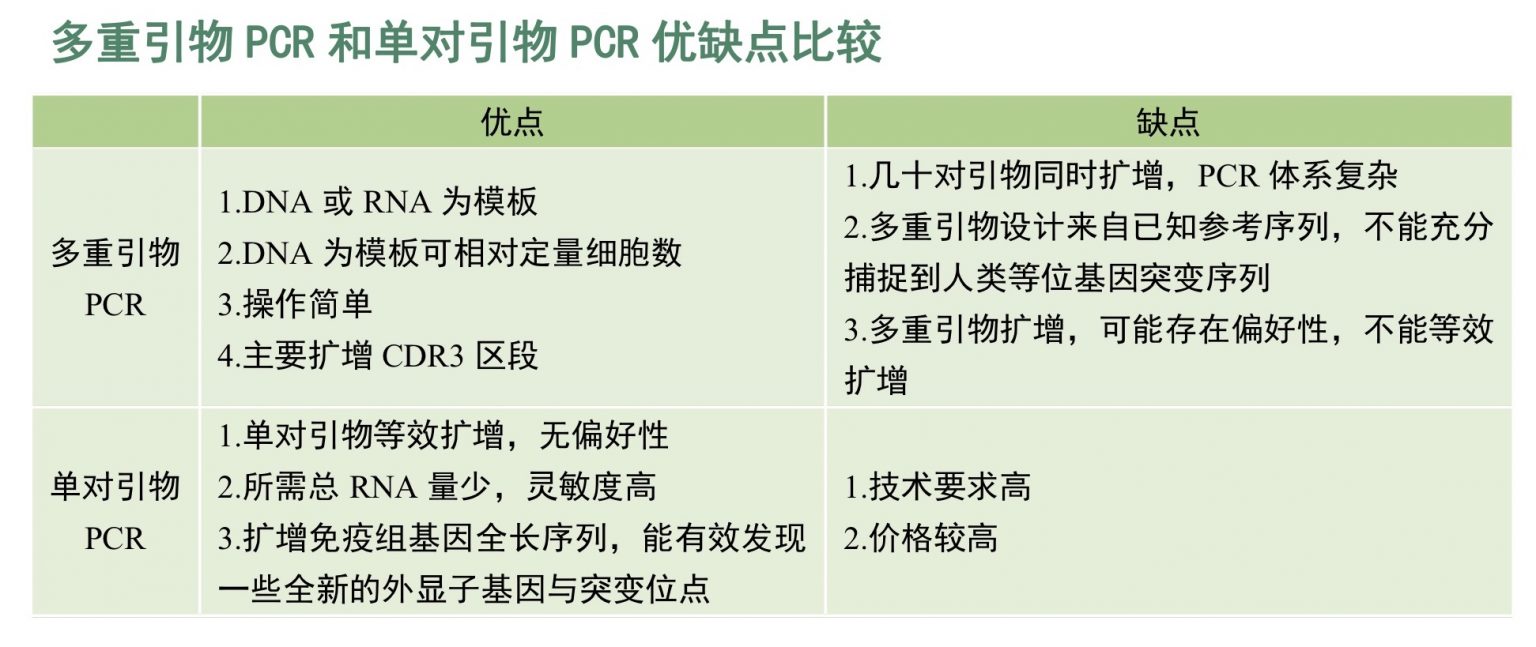
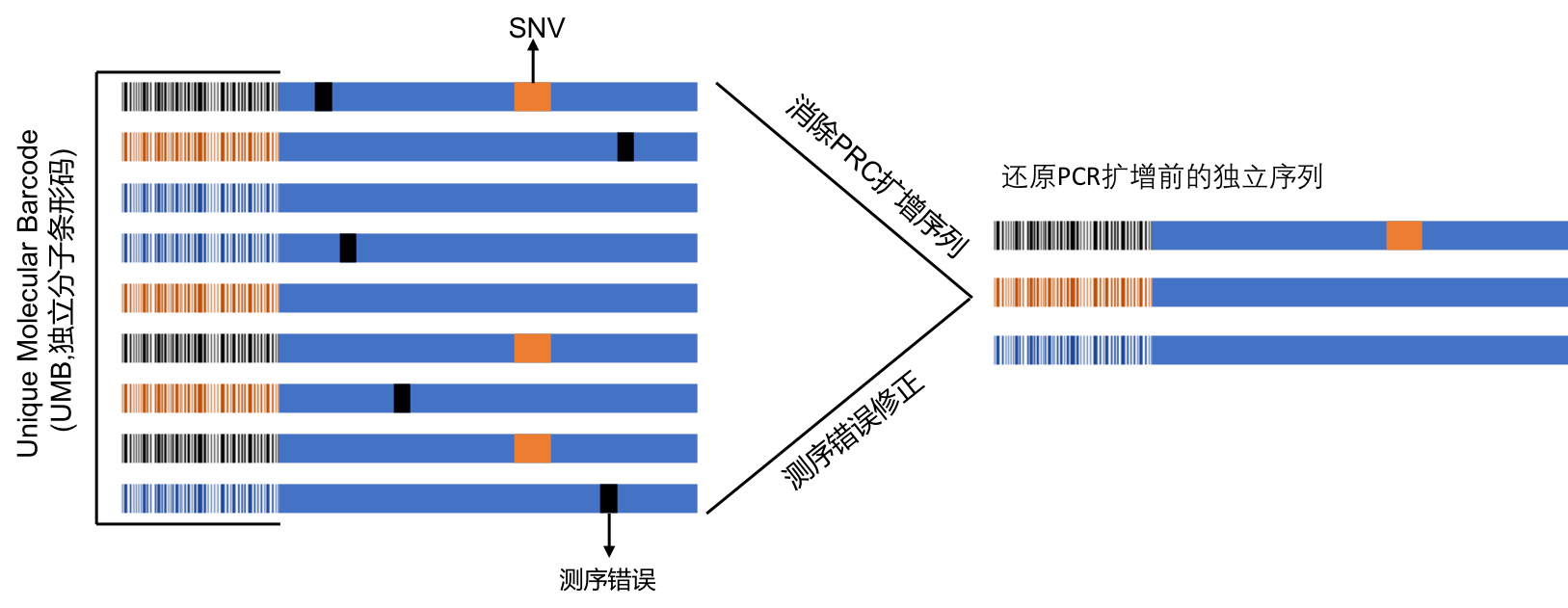
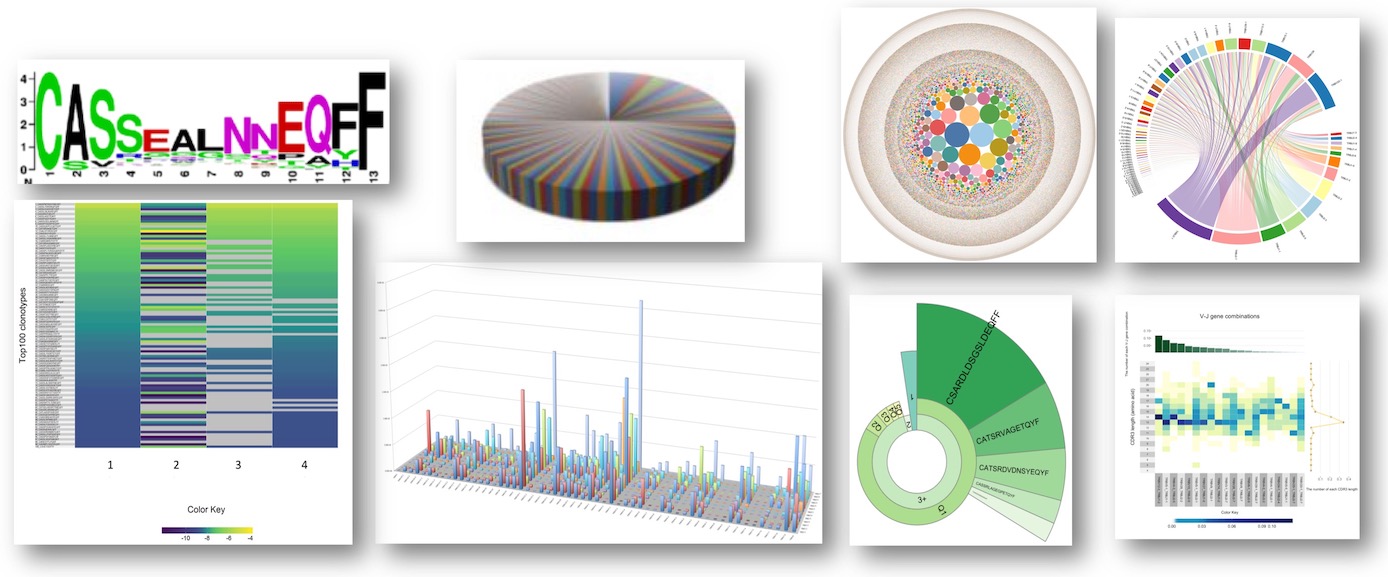
服务流程:客户提供样本,通常为全血、骨髓、单个核细胞、分离后的B细胞、RNA/cDNA或者石蜡包埋的组织[FFPE],送达公司实验室后,实验室根据样本的情况,进行血液或骨髓的B细胞分离→ RNA 提取→ cDNA 合成→测序文库构建→第二代基因测序→生物信息学处理→数据分析和出图→临床信息分析(如下图)。 45个工作日后客户获得测序结果报告。
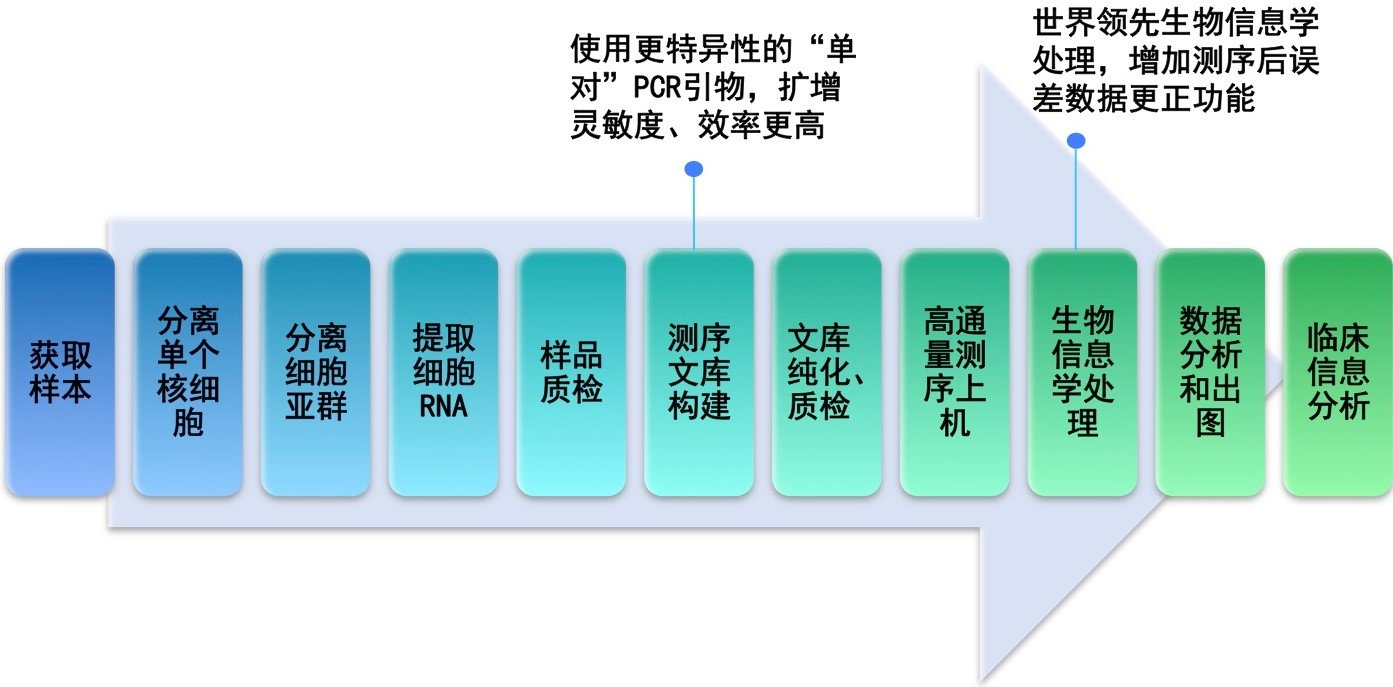

服务流程:客户提供样本,通常为全血、骨髓、单个核细胞、分离后的B细胞、RNA/cDNA或者石蜡包埋的组织[FFPE],送达公司实验室后,实验室根据样本的情况,进行血液或骨髓的B细胞分离→ RNA 提取→ cDNA 合成→测序文库构建→第二代基因测序→生物信息学处理→数据分析和出图→临床信息分析(如下图)。 45个工作日后客户获得测序结果报告。