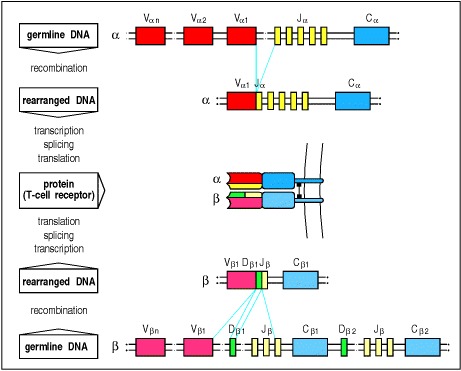
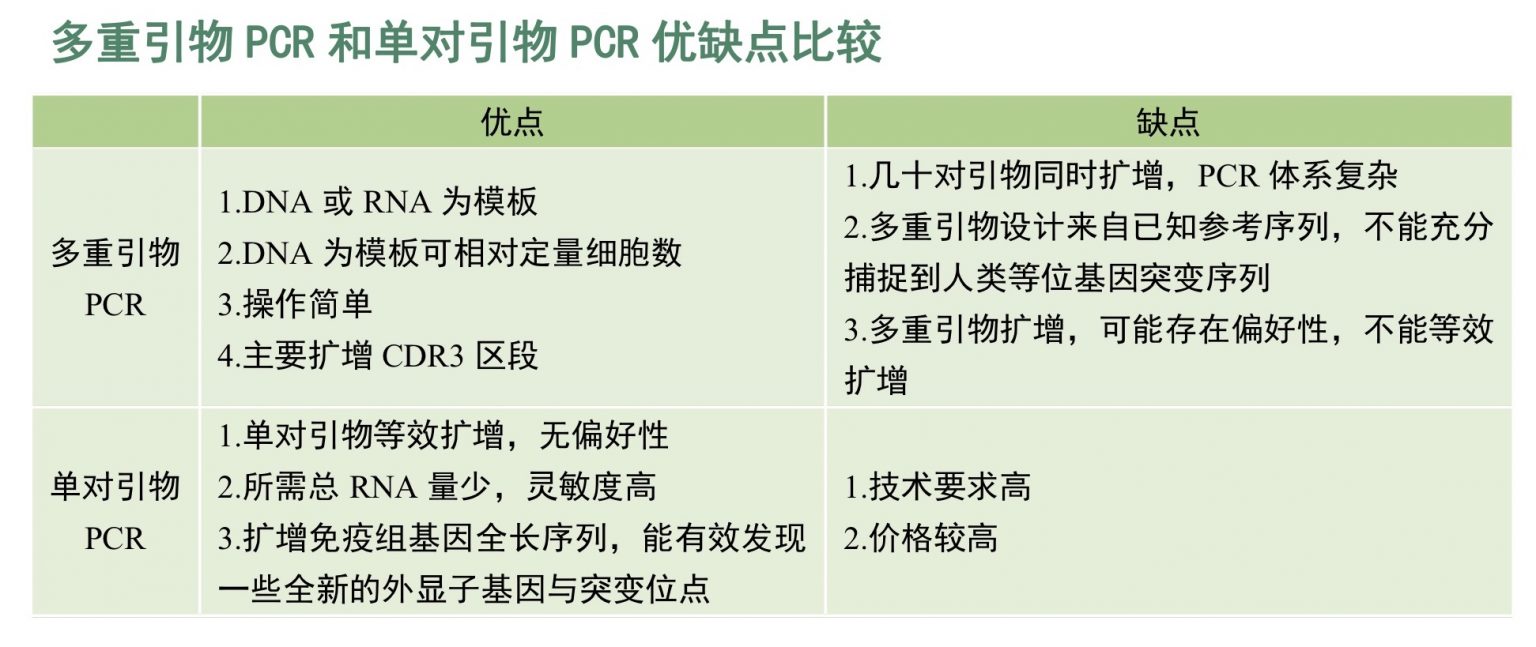
更少实验误差,更全面准确的分析
• 基于 RNA 的分析检测,这样除去了内含子,避免了不必要的引物及消耗和结果误差,获得的数据是基于表达的(有功能的)T、B细胞受体;
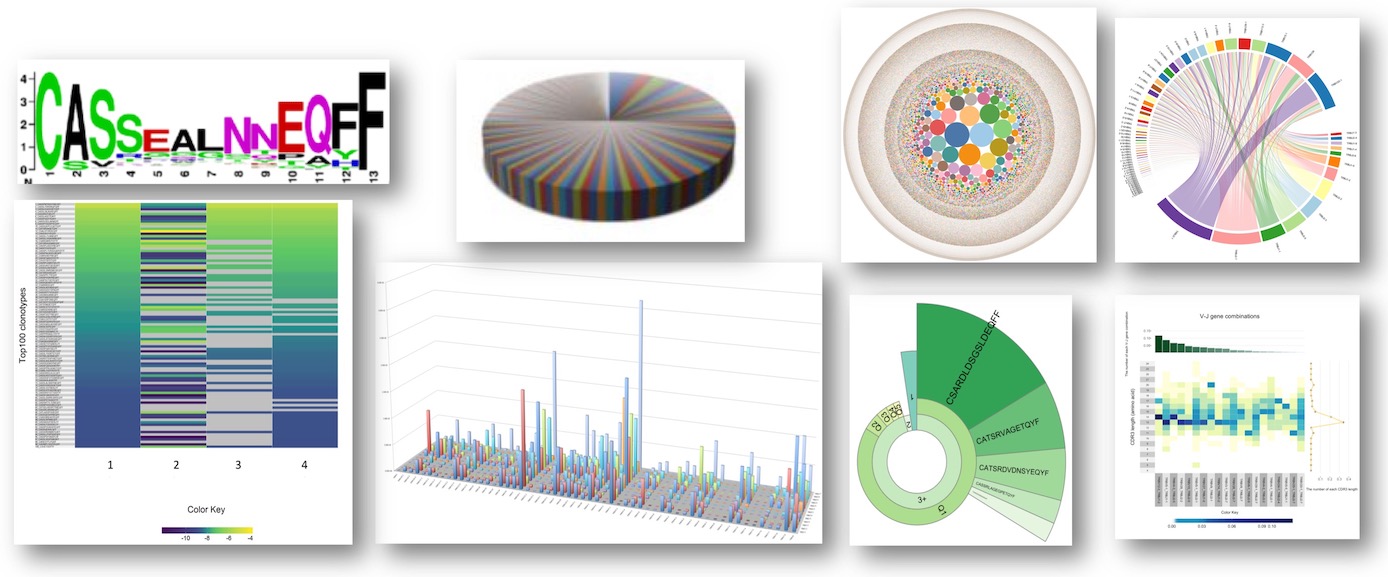
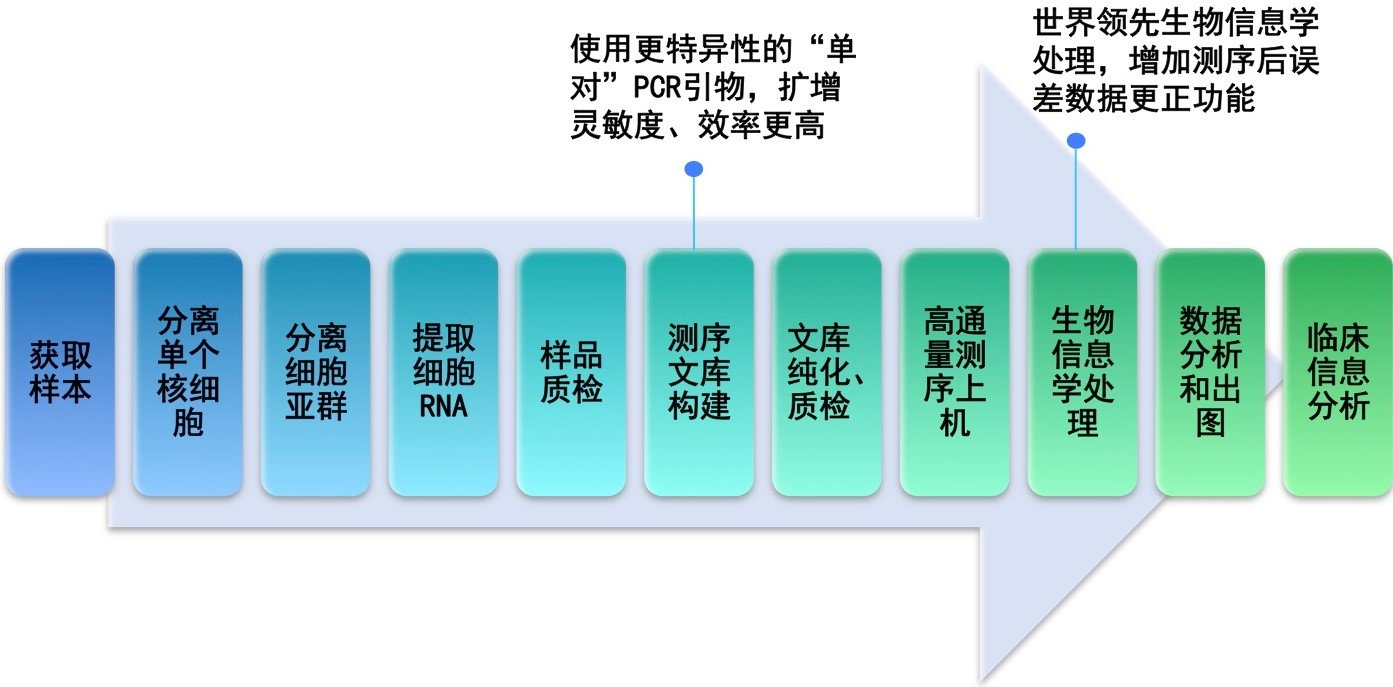
• 单对引物(5‘RACE)方法文库构建准确率高,测序数据与IMGT ® 数据库基因座匹配正确率可达97%-99.7%,并能扩增TCR和BCR的V-(D)-J 序列全长(包括 FR1-4 和 CDR1-3);
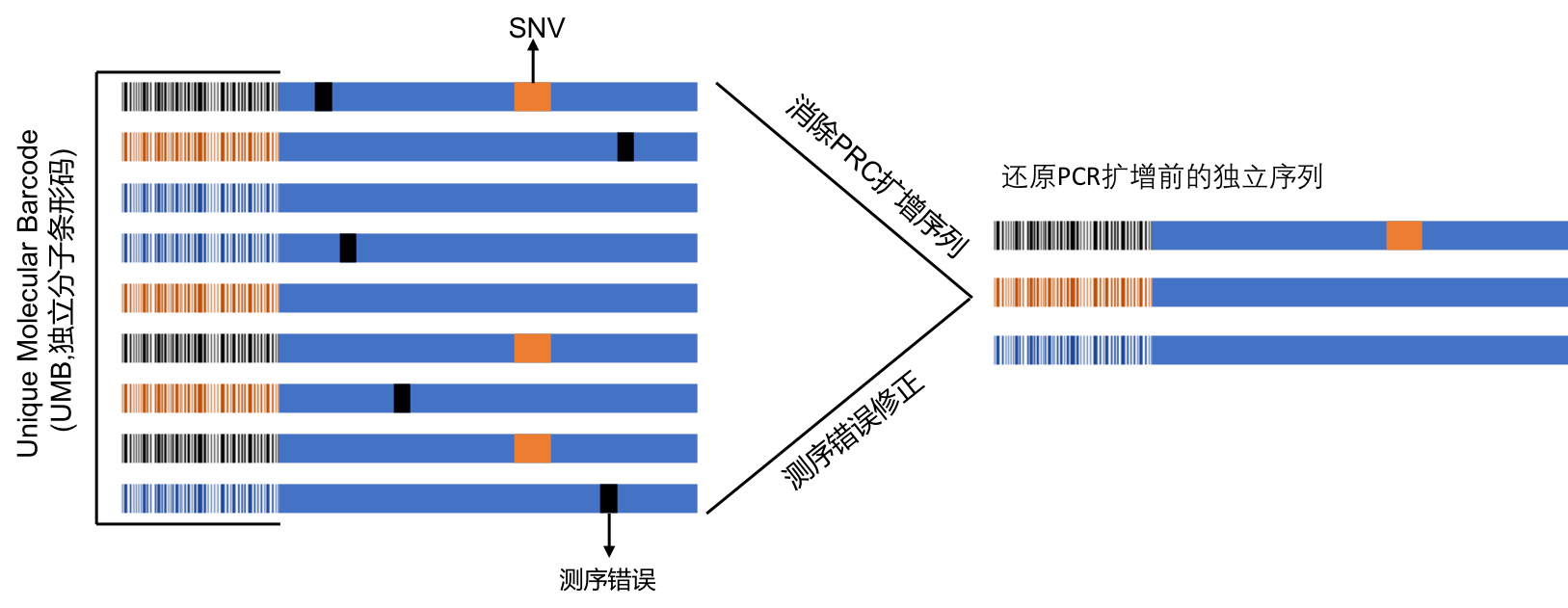
• 深度测序并使用世界领先生物信息学分析算法对数据进行处理,可进行下机数据全自动生信分析(无人值守)及纠错,纠正PCR和测序引入的错误,有更强的纠错能力和错配处理能力,更大程度的获得有效数据,挖掘测序获得的有效信息;
• 自主研发PCR反应体系稳定,接头序列连接效率高、目标基因扩增效率高;扩增灵敏度极高,RNA模板量最小化,最低可达10ng,为小或珍惜临床样本(如肿瘤病人骨髓或穿刺样本)获得测序可能性;
• BCR文库构建使用的优化引物可有效鉴别更多IGH链亚型,如IgA1, IgA2,IgG1, IgG2, IgG3, IgG4,IgE,IgM等;
• 相对多重PCR技术,可以完全避免引物偏好性。