
2026еєі5жЬИпЉМжЦѓеЭ¶з¶Пе§Іе≠¶K. Christopher GarciaеЫҐйШЯиБФеРИиКЭеК†еУ•е§Іе≠¶Aly A. KhanеЫҐйШЯдЇОгАКNature BiotechnologyгАЛеИКеПСжЬАжЦ∞з†Фз©ґгАВиѓ•з†Фз©ґиЮНеРИйЂШйАЪйЗПйЕµжѓНе±Хз§ЇжКАжЬѓдЄОиЫЛзЩљиі®иѓ≠и®Аж®°еЮЛпЉМжИРеКЯжЮДеїЇTзїЖиГЮеПЧдљУпЉИTCRпЉЙиВљжЃµиѓЖеИЂеЕ®жЩѓеЫЊи∞±пЉИPRPsпЉЙгАВз†Фз©ґиѓБеЃЮпЉМTCRзЪДеКЯиГљжіїжАІдЄїи¶БзФ±еЕґжКЧеОЯиѓЖеИЂж®°еЉПеЖ≥еЃЪпЉМиАМйЭЮж∞®еЯЇйЕЄеЇПеИЧзЫЄдЉЉеЇ¶пЉЫеРМжЧґз≠ЫйАЙеЗЇеЉЇзЫіжАІиДКжЯ±зВОз≠ЙиЗ™иЇЂеЕНзЦЂзЧЕзЫЄеЕ≥жЦ∞еЮЛжКЧеОЯпЉМдЄЇеЕНзЦЂзЦЊзЧЕжЬЇеИґжОҐз©ґеПКеЕНзЦЂж≤їзЦЧз†ФеПС商еЃЪдЇЖеЕ®жЦ∞жКАжЬѓеЯЇз°АгАВ


жСШи¶Б
TзїЖиГЮеПЧдљУпЉИTCRпЉЙзЪДжКЧеОЯзЙєеЉВжАІжЧ†ж≥ХдїЕйАЪињЗеЇПеИЧдњ°жБѓињЫи°МеПѓйЭ†йҐДжµЛпЉМеЇПеИЧйЂШеЇ¶зЫЄдЉЉзЪДTCRеПѓиГљиѓЖеИЂеЃМеЕ®дЄНеРМзЪДжКЧеОЯпЉМиАМеЇПеИЧеЈЃеЉВжШЊиСЧзЪДTCRеНіеПѓиГљиѓЖеИЂеРМдЄАжКЧеОЯгАВжЬђз†Фз©ґжЮДеїЇдЇЖдЄАе•ЧжХіеРИеЃЮй™МдЄОиЃ°зЃЧзЪДжКАжЬѓдљУз≥їпЉМйАЪињЗйЂШйАЪйЗПйЕµжѓНе±Хз§ЇжКАжЬѓдЄОеЊЃи∞ГеРОзЪДиЫЛзЩљиі®иѓ≠и®Аж®°еЮЛпЉИpLMsпЉЙзЫЄзїУеРИпЉМдЄЇеНХдЄ™TCRзФЯжИРиВљиѓЖеИЂеЕ®жЩѓеЫЊи∞±пЉИPRPsпЉЙпЉМеЕ®йЭҐиІ£жЮРеЕґдЄОжХ∞зЩЊдЄЗзІНиВљжЃµзЪДзїУеРИзЙєжАІгАВ
жЬђз†Фз©ґиБЪзД¶дЇОеЉЇзЫіжАІиДКжЯ±зВОдЄОжА•жАІеЙНиС°иРДиЖЬзВОжВ£иАЕжЭ•жЇРзЪДHLA-B*27:05йЩРеИґжАІTCRпЉМж≠§з±їTCRзЪДжКЧеОЯиѓЖеИЂдЄїи¶БзФ±CDR3ќ≤йУЊдїЛеѓЉгАВеЯЇдЇОPRPsиЃ≠зїГзЪДж®°еЮЛпЉМеЬ®TзїЖиГЮжіїеМЦйҐДжµЛдїїеК°дЄ≠зЪДжАІиГљжШЊиСЧдЉШдЇОAlphaFold3з≠ЙдЉ†зїЯзїУжЮДйҐДжµЛеЈ•еЕЈгАВ
з†Фз©ґиѓБеЃЮпЉМж®°еЮЛеѓєжЦ∞TCRзЪДж≥ЫеМЦиГљеКЫдЄОеКЯиГљиЈЭз¶їпЉИPRPеЈЃеЉВеЇ¶пЉЙйЂШеЇ¶зЫЄеЕ≥пЉМиАМйЭЮеЇПеИЧзЫЄдЉЉжАІпЉЫеРМжЧґеЉХеЕ•дЇЖж®°еЮЛеЫЇжЬЙдЄНз°ЃеЃЪжАІжМЗж†Здї•йЗПеМЦйҐДжµЛзљЃдњ°еЇ¶пЉМдЄЇзЦЊзЧЕзЫЄеЕ≥жКЧеОЯзЪДеПСзО∞еПКTCRеЈ•з®ЛеМЦжФєйА†жПРдЊЫдЇЖйЂШжХИгАБеПѓиІДж®°еМЦзЪДжКАжЬѓиЈѓеЊДгАВ

еЉХи®А
TCRиѓЖеИЂжКЧеОЯиВљ-MHCе§НеРИзЙ©жШѓйАВеЇФжАІеЕНзЦЂзЪДж†ЄењГпЉМдљЖTCRеЇПеИЧдЄОжКЧеОЯзЙєеЉВжАІжЧ†еЫЇеЃЪеѓєеЇФеЕ≥з≥їпЉМдЉ†зїЯеЇПеИЧеИЖжЮРж≥ХгАБдЄїжµБзїУжЮДйҐДжµЛж®°еЮЛеЭЗе≠ШеЬ®жШОжШЊзЯ≠жЭњпЉМйЪЊдї•жМЦжОШиЗ™иЇЂеЕНзЦЂзЧЕзЫЄеЕ≥йЪРиФљжКЧеОЯгАВжЬђз†Фз©ґжХіеРИйЂШйАЪйЗПеЃЮй™МдЄОжЬЇеЩ®е≠¶дє†жКАжЬѓпЉМжЮДеїЇеє≥еП∞еєґзїШеИґTCRиВљиѓЖеИЂеЕ®жЩѓеЫЊи∞±гАВиѓ•дљУз≥їеПѓз≤ЊеЗЖйҐДжµЛTзїЖиГЮжіїеМЦпЉМжИРеКЯйЙіеЃЪеЗЇеЉЇзЫіжАІиДКжЯ±зВОгАБжА•жАІеЙНиС°иРДиЖЬзВОзЪДжЦ∞еЮЛиЗ™иЇЂжКЧеОЯпЉМеРМжЧґжШОз°Ѓж®°еЮЛж≥ЫеМЦдЊЭжНЃдЄЇTCRеКЯиГљеЈЃеЉВпЉМдЄЇеЕНзЦЂз†Фз©ґдЄОеЕНзЦЂзЦЧж≥Хз†ФеПСжПРдЊЫдЇЖжЦ∞жЦєж°ИгАВ

жЦєж≥Х
дЄАгАБTCRз≠ЫйАЙ
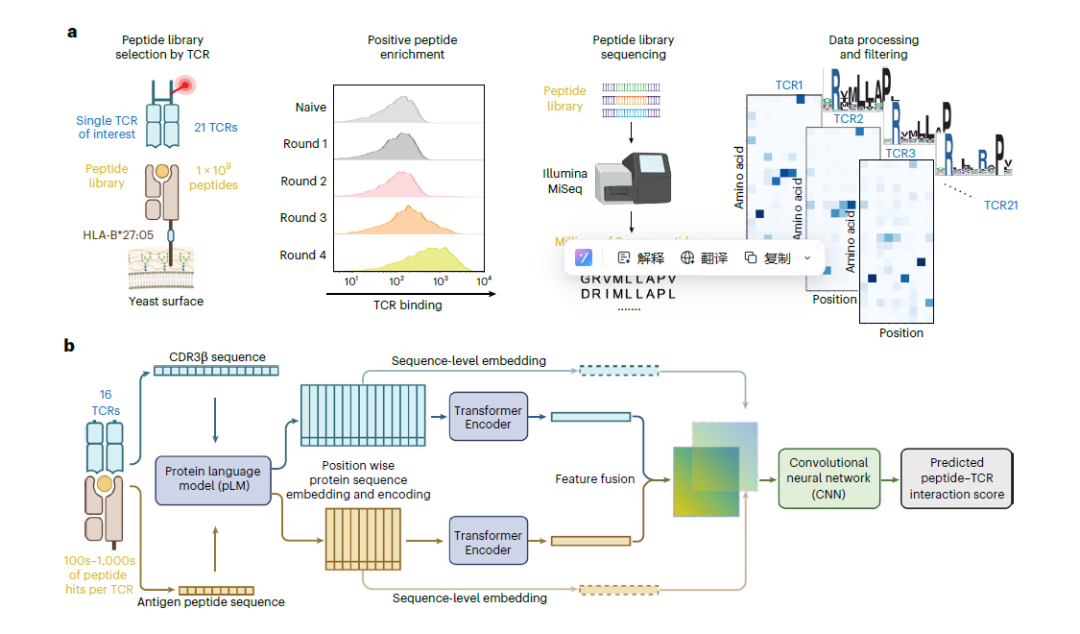
з†Фз©ґеЕ±зЇ≥еЕ•16зІНжЭ•иЗ™еЉЇзЫіжАІиДКжЯ±зВОгАБжА•жАІеЙНиС°иРДиЖЬзВОж†ЈжЬђзЪДзЦЊзЧЕзЫЄеЕ≥TCRпЉМеИЖдЄЇдЄЙз±їпЉЪ
пЉИ1пЉЙеЕђеЕ±еЃґжЧПTCRпЉЪеРЂTCR4.1гАБ8.4гАБ9.1пЉМеЭЗдЄЇHLA-B*27йШ≥жАІжВ£иАЕжЭ•жЇРпЉМзїПжµБеЉПеИЖйАЙгАБеНХзїЖиГЮжµЛеЇПиОЈеЊЧпЉМе±ЮзїПеЕЄBV9еЕђеЕ±еЃґжЧПгАВ
пЉИ2пЉЙйЭЮBV9 TCRпЉЪдї•TCR019.1дЄЇдї£и°®пЉМеПЦиЗ™иС°иРДиЖЬзВОжВ£иАЕжИњж∞іпЉМдЄНжРЇеЄ¶зїПеЕЄеЯЇеЇПпЉМжЛУе±ХдЇЖTCRеЃґжЧПиМГеЫігАВ
пЉИ3)YeiHеЫЫиБЪдљУеИЖйАЙTCRпЉЪеРЂ9зІНTCRпЉМжЭ•иЗ™жВ£иАЕе§ЦеС®и°АпЉМзїПжКЧеОЯзЙєеЉВжАІеЫЫиБЪдљУз≠ЫйАЙпЉМи¶ЖзЫЦе§ЪзІНеЕЛйЪЖеЮЛгАВ
дЇМгАБеЈ•з®ЛеМЦTCRдЄОќ±йУЊдЇТжНҐ
жЮДеїЇз™БеПШдљУпЉЪеЬ® TCR19.2зЪДCDR3ќ≤еЉХеЕ•1-3дЄ™ж∞®еЯЇйЕЄз™БеПШпЉМдњЭзХЩ ќ±йУЊпЉМиОЈеЊЧ5зІНеЈ•з®ЛеПШдљУпЉМзФ®дЇОж®°еЮЛж≥ЫеМЦжµЛиѓХгАВ
жЮДеїЇеµМеРИTCRпЉЪдЇТжНҐеМєйЕНзЪДќ±йУЊпЉМй™МиѓБќ≤йУЊдЄїеѓЉиѓЖеИЂзЪДжЬЇеИґпЉМеЬ®зїЖиГЮдЄ≠и°®иЊЊеєґж£АжµЛжіїеМЦеЈЃеЉВгАВ
дЄЙгАБPSG5еЫЫиБЪдљУжµБеЉПж£АжµЛ
дЉ¶зРЖдЄОеЕ•зїДпЉЪз†Фз©ґзђ¶еРИдЉ¶зРЖпЉМжВ£иАЕдЄ•ж†ЉжМЙзЦЊзЧЕж†ЗеЗЖеЕ•зїДпЉМеБ•еЇЈеѓєзЕІжЧ†иЗ™иЇЂеЕНзЦЂзЧЕпЉМеЭЗз°ЃиЃ§дЄЇHLA-B*27йШ≥жАІгАВ
ж†ЈжЬђе§ДзРЖпЉЪйЗЗйЫЖе§ЦеС®и°АпЉМеИЖз¶їеЖїе≠ШеЕНзЦЂзїЖиГЮпЉМзФ®дЇОеРОзї≠жµБеЉПж£АжµЛгАВ
жµБеЉПжЯУиЙ≤пЉЪзФ®PSG5з≠ЙзЙєеЉВжАІеЫЫиБЪдљУж†ЗиЃ∞зїЖиГЮпЉМжЯУиЙ≤гАБеЫЇеЃЪеРОдЄКжЬЇж£АжµЛпЉМеИЖжЮРжКЧеОЯзЙєеЉВжАІTзїЖиГЮйҐСзОЗгАВ
еЫЫгАБTCRиЫЛзЩљи°®иЊЊ
е∞ЖTCRќ±/ќ≤йУЊеЕЛйЪЖиЗ≥иљљдљУпЉМеЕ±иљђжЯУExpi293зїЖиГЮпЉМи°®иЊЊеРОзїПдЇ≤еТМгАБжµУзЉ©гАБзФЯзЙ©зі†еМЦгАБе±ВжЮРзЇѓеМЦпЉМиОЈеЊЧйЂШзЇѓеЇ¶TCRгАВ
дЇФгАБйЕµжѓНиВљжЦЗеЇУжЮДеїЇдЄОз≠ЫйАЙ
жЮДеїЇеРЂеЫЇеЃЪйФЪеЃЪжЃЛеЯЇзЪД9иВљйЕµжѓНжЦЗеЇУпЉМзїПе§ЪиљЃйШ≥жАІгАБйШіжАІз≠ЫйАЙпЉМеѓМйЫЖзЙєеЉВжАІиВљеЇПеИЧпЉМзФ®дЇОжЈ±еЇ¶жµЛеЇПгАВ
еЕ≠гАБжЦЗеЇУжЈ±еЇ¶жµЛеЇП
жПРеПЦйЕµжѓНDNAпЉМжЙ©еҐЮиВљеЇПеИЧпЉМжµЛеЇПеРОеИЖжЮРеѓМйЫЖиВљзІНз±їгАБжХ∞йЗПпЉМжЮДеїЇ TCRиѓЖеИЂжХ∞жНЃйЫЖгАВ
дЄГгАБT зїЖиГЮжіїеМЦеЃЮй™М
иљљдљУжЮДеїЇпЉЪе∞ЖTCRгАБHLAеИЖеИЂеѓЉеЕ•жЕҐзЧЕжѓТиљљдљУпЉМжДЯжЯУзїЖиГЮиОЈеЊЧз®≥еЃЪи°®иЊЊзїЖиГЮз≥їгАВ
еЕ±еЯєеЕїж£АжµЛпЉЪжКЧеОЯеСИйАТзїЖиГЮиіЯиљљиВљпЉМдЄОTзїЖиГЮеЕ±еЯєеЕїпЉМж£АжµЛжіїеМЦж†ЗењЧзЙ©гАВ
еЕЂгАБHLAиЫЛзЩљеОЯж†Єи°®иЊЊ
HLAйЗНйУЊгАБќ≤2mеЬ®е§ІиВ†жЭЖиПМдЄ≠дї•еМЕжґµдљУи°®иЊЊпЉМи£ВиІ£жіЧ洧еРОжЇґиІ£е§ЗзФ®гАВ
дєЭгАБpMHCе§НжАІ
е∞ЖиВљгАБHLAйЗНйУЊгАБќ≤2mжЈЈеРИе§НжАІпЉМйАПжЮРзЇѓеМЦпЉМиОЈеЊЧеКЯиГљжАІpMHCе§НеРИзЙ©гАВ
еНБгАБе§НеРИзЙ©зїУжЩґдЄОзїУжЮДиІ£жЮР
зЇѓеМЦTCR-pMHCе§НеРИзЙ©пЉМзїУжЩґгАБи°Не∞ДгАБиІ£жЮРеОЯе≠РзїУжЮДпЉМйШРжШОиѓЖеИЂжЬЇеИґгАВ

зїУжЮЬ
дЄАгАБжР≠еїЇжХіеРИеє≥еП∞пЉМзїШеИґTCR-иВљиѓЖеИЂеЕ®жЩѓеЫЊи∞±
жЙУйА†еЃЮй™МдЄОиЃ°зЃЧзїУеРИзЪДжКАжЬѓеє≥еП∞,иІ£жЮРTCRдЄОиВљжКЧеОЯзЪДдљЬзФ®иІДеЊЛгАВеАЯеК©йЂШйАЪйЗПйЕµжѓНе±Хз§ЇиБФеРИдЇМдї£жµЛеЇПжКАжЬѓпЉМж£АжµЛTCRеТМиВљжЃµзЪДзїУеРИжГЕеЖµгАВйТИеѓєзЙєеЃЪеИЖеЮЛиЃЊиЃ°иВљеЇУпЉМеЫЇеЃЪеЕ≥йФЃйФЪеЃЪж∞®еЯЇйЕЄпЉМеЕЉй°ЊиВљеЇУз®≥еЃЪжАІдЄОж£АжµЛеЕ®йЭҐжАІгАВеЫҐйШЯеИ©зФ®16зІНеЕ≥иБФеЉЇзЫіжАІиДКжЯ±зВОгАБжА•жАІеЙНиС°иРДиЖЬзВОзЪДTCRеЃМжИРжµЛиѓХпЉМеЊЧеИ∞жµЈйЗПиѓЖеИЂжХ∞жНЃпЉМеєґзїУеРИиЫЛзЩљиі®иѓ≠и®Аж®°еЮЛеїЇж®°еИЖжЮРTCRдљЬзФ®иІДеЊЛгАВ
дљЬиАЕйАЪињЗFig.2зїЩеЗЇдЇЖжХізѓЗжЦЗзЂ†зЪДж†ЄењГпЉЪPRPдЄНжШѓзїЩTCRеБЪжЩЃйАЪеИЖз±їпЉМиАМжШѓжККTCRжФЊињЫвАЬиВљиѓЖеИЂз©ЇйЧівАЭйЗМйЗНжЦ∞еЃЪдљНгАВзЬЯж≠£иГљеЃЪдєЙTCRеЕ≥з≥їзЪДпЉМжШѓеЃГдїђиѓЖеИЂиВљзЪДжХідљУж®°еЉПгАВ
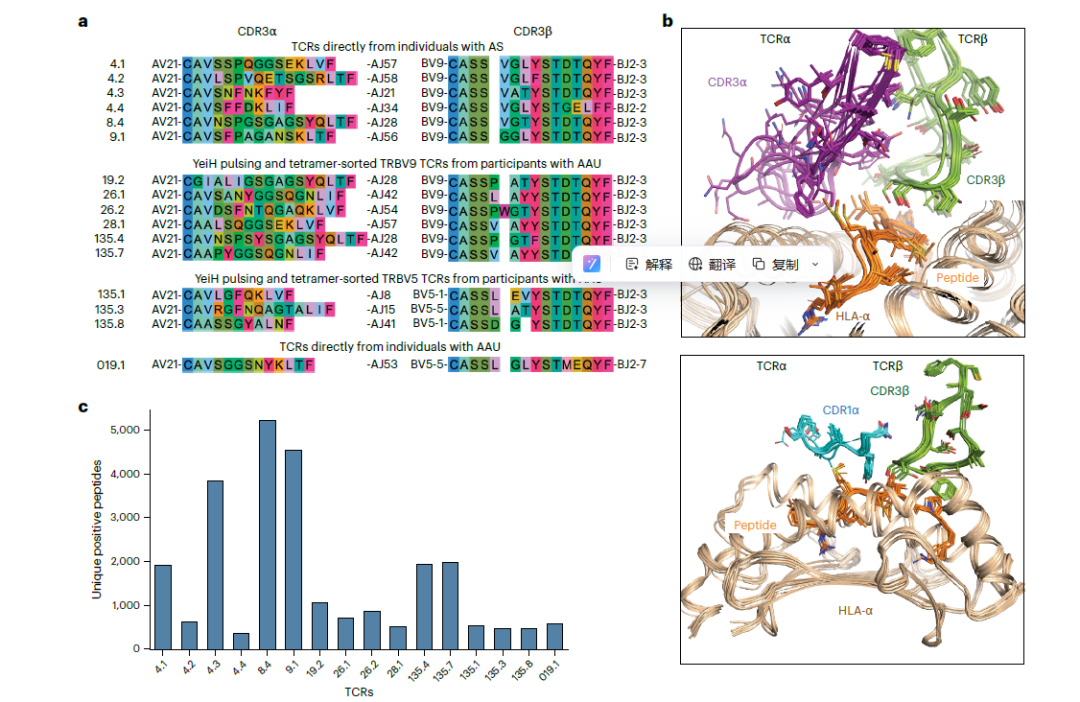
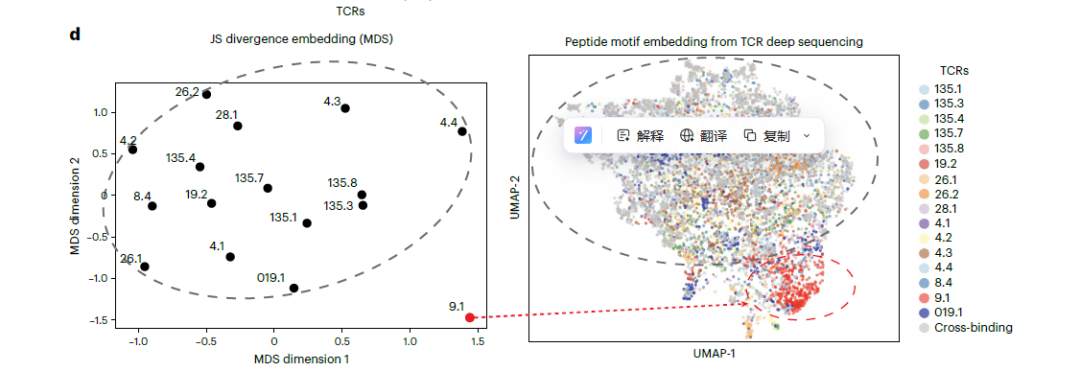
Fig.2дїОеЇПеИЧгАБзїУжЮДеИ∞еКЯиГљпЉМе±Ве±ВйАТињЫеЬ∞жП≠з§ЇдЇЖHLA-B*27зЫЄеЕ≥TCRзЪДе§Ъж†ЈжАІпЉЪ
еЇПеИЧвЙ†еКЯиГљпЉЪеН≥дљњеЇПеИЧзЫЄдЉЉпЉМTCRзЪДдЇ§еПЙеПНеЇФжАІеТМиВљиѓЖеИЂи∞±дєЯеПѓиГљеЃМеЕ®дЄНеРМгАВ
зїУжЮДеЖ≥еЃЪзЙєеЉВжАІпЉЪќ≤йУЊдЄїеѓЉзЪДиѓЖеИЂж®°еЉПжШѓињЩз±їTCRзЪДеЕ±жАІзЙєеЊБгАВ
еКЯиГљиЈЭз¶їжШѓеЕ≥йФЃпЉЪеЯЇдЇОиВљиѓЖеИЂеЕ®жЩѓеЫЊи∞±зЪДеИЖжЮРпЉМжѓФдЉ†зїЯзЪДеЇПеИЧеИЖжЮРжЫіиГљеПНжШ†TCRзЪДзЬЯеЃЮзЙєеЉВжАІгАВ
ињЩдєЯжШѓеРОзї≠з†Фз©ґдЄ≠пЉМж®°еЮЛйҐДжµЛжАІиГљдЉШдЇОдЉ†зїЯеЇПеИЧ/зїУжЮДжЦєж≥ХзЪДж†єжЬђеОЯеЫ†гАВ
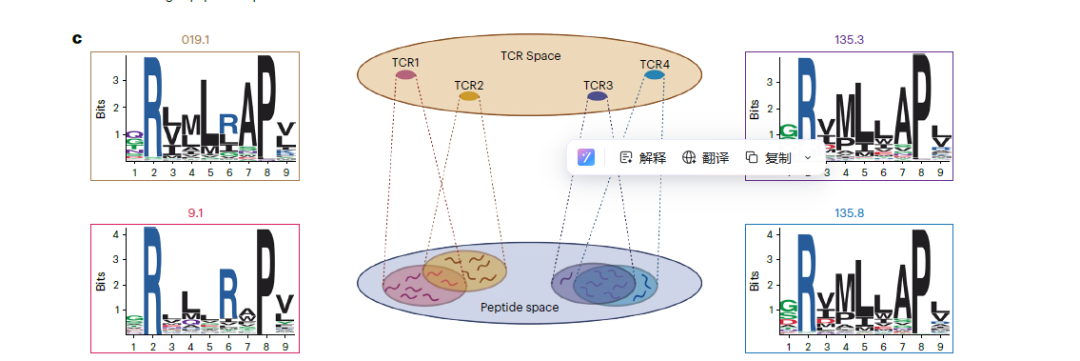
дЇМгАБPRPsиѓБеЃЮTCRеКЯиГљиБЪз±їеТМеЇПеИЧзЫЄдЉЉжАІжЧ†еЕ≥
йАЙзФ®16зІНиЗізЧЕзЫЄеЕ≥TCRпЉМеЕґCDR3еМЇеЯЯе≠ШеЬ®жШОжШЊеЇПеИЧеЈЃеЉВгАВзїУжЮДеИЖжЮРжШЊз§ЇпЉМињЩз±їTCRдЄїи¶БдЊЭйЭ†ќ≤йУЊеЃЮзО∞дЄОиВљжЃµзЪДзїУеРИгАВйАЪињЗиЃ°зЃЧеКЯиГљиЈЭз¶їгАБе§Ъзїіж†ЗеЇ¶еПѓиІЖеМЦз≠ЙжЦєеЉПеИЖжЮРеПСзО∞пЉМTCRдЉЪдЊЭжНЃиВљиѓЖеИЂеБП啚嚥жИРзЛђзЂЛз±їзЊ§пЉМиѓ•иБЪз±їзїУжЮЬеТМеЯЇеЫ†еЇПеИЧзЫЄдЉЉеЇ¶ж≤°жЬЙеЕ≥иБФпЉМдєЯйАЪињЗе§ЪзІНйЩНзїізЃЧж≥Хй™МиѓБдЇЖзїУиЃЇзЪДз®≥еЃЪжАІгАВ
дЄЙгАБдЊЭжЙШPRPдЉШеМЦж®°еЮЛпЉМз≤ЊеЗЖйҐДжµЛиВљжЃµзїУеРИзЙєжАІ
еИ©зФ®иВљиѓЖеИЂеЫЊи∞±жХ∞жНЃеЊЃи∞ГиЫЛзЩљиі®иѓ≠и®Аж®°еЮЛпЉМж®°еЮЛеПѓйЂШжХИеМЇеИЖзїУеРИдЄОйЭЮзїУеРИиВљжЃµгАВеЃЮй™МеѓєжѓФеПСзО∞пЉМжЦ∞еҐЮќ±йУЊеЇПеИЧеєґдЄНиГљжПРеНЗйҐДжµЛжХИжЮЬпЉМиѓБжШОќ≤йУЊжШѓеЖ≥еЃЪиВљиѓЖеИЂзЙєеЉВжАІзЪДж†ЄењГгАВеєґдЄФеЃЪдљНеЗЇељ±еУНзїУеРИжХИжЮЬзЪДеЕ≥йФЃж∞®еЯЇйЕЄдљНзВєпЉМеРМжЧґеИ©зФ®ж®°еЮЛз≠ЫжЯ•дЇЇз±їиЫЛзЩљзїДпЉМз≠ЫйАЙеЗЇеНБдљЩзІНеПѓзїУеРИе§ЪзІНиЗізЧЕTCRзЪДжљЬеЬ®иЗ™иЇЂжКЧеОЯгАВ
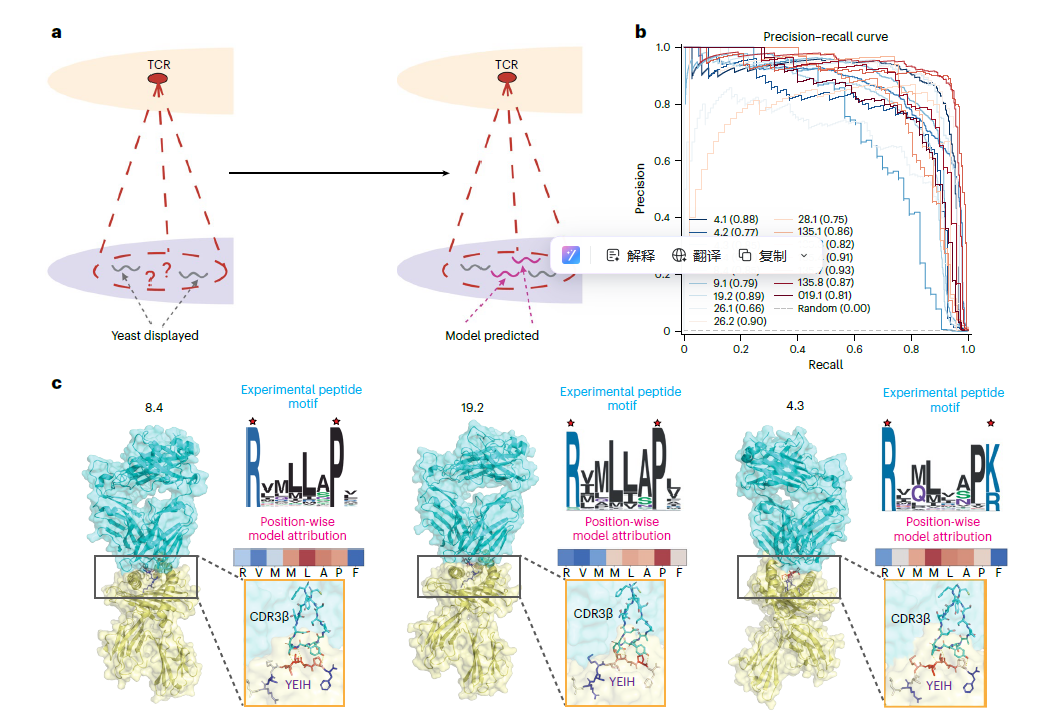
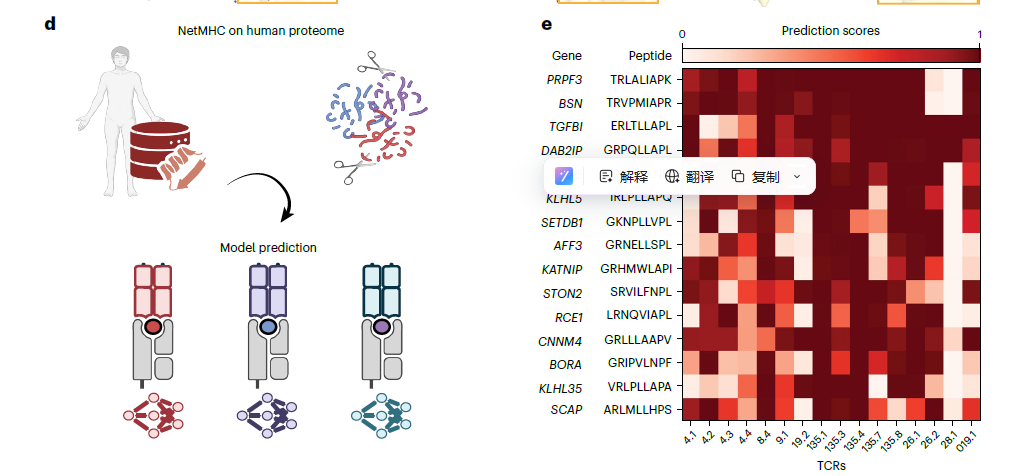
Fig.3зЫіиІВе±Хз§ЇдЇЖж®°еЮЛзЪДж†ЄењГдљЬзФ®пЉЪзФ®PRPиЃ≠зїГиЫЛзЩљиѓ≠и®Аж®°еЮЛпЉМиЃ©ж®°еЮЛе≠¶дЉЪTCRиѓЖеИЂиВљзЪДиІДеИЩзЪДж≠•й™§гАВ
зїУжЮДиГМжЩѓпЉЪе±Хз§ЇдЇЖTCR8.4гАБ19.2гАБ4.3дЄОHLA-B*27:05-иВље§НеРИзЙ©зЪДзїУжЮДгАВ
еЃЮй™МиВљеЯЇеЇПпЉЪдЄКжЦєзЪДеЇПеИЧLogoеЫЊпЉМжШѓдїОйЕµжѓНе±Хз§ЇжХ∞жНЃдЄ≠еЊЧеИ∞зЪДзЬЯеЃЮзїУеРИиВљжЃµзЪДеБПе•љжАІгАВ
еЫЫгАБж®°еЮЛеПѓжЬЙжХИйҐДжµЛиВљжЃµеЉХеПСзЪДTзїЖиГЮжіїеМЦеПНеЇФ
TзїЖиГЮжіїеМЦжШѓи°°йЗПзЫЄдЇТдљЬзФ®зЪДж†ЄењГжМЗж†ЗпЉМеЃЮй™МиѓБеЃЮиѓ•ж®°еЮЛиГљз≤ЊеЗЖеМЇеИЖеПѓжњАжіїTзїЖиГЮзЪДиВљжЃµпЉМжАІиГљдЉШдЇОдЉ†зїЯзїУжЮДйҐДжµЛеЈ•еЕЈгАВз†Фз©ґз≠ЫйАЙеЗЇе§ЪзІНжЦ∞еЮЛиЗ™иЇЂжКЧеОЯпЉМеЕґдЄ≠йГ®еИЖиВљжЃµжњАжіїиГљеКЫеЉЇдЇОеЈ≤зЯ•жКЧеОЯгАВеНХзЛђдЊЭйЭ†MHCеЉЇзїУеРИиГљеКЫжЧ†ж≥ХеЃЮзО∞TзїЖиГЮжіїеМЦпЉМиАМжЇРиЗ™PSG5зЪДиВљжЃµе•СеРИзЧЕзЧЗеПСзЧЕйГ®дљНпЉМ襀иѓБеЃЮжШѓдЄ§з±їиЗ™иЇЂеЕНзЦЂзЧЕзЪДеЕ®жЦ∞еАЩйАЙжКЧеОЯгАВ
Fig.4жШѓиѓ•з†Фз©ґзЪДвАЬй™МиѓБйЧ≠зОѓвАЭпЉМеЃГдїОзїЖиГЮеКЯиГљгАБжКЧеОЯеПНеЇФгАБдЄіеЇКзЫЄеЕ≥жАІеТМзїУжЮДиІ£жЮРеЫЫдЄ™е±ВйЭҐпЉМй™МиѓБдЇЖж®°еЮЛйҐДжµЛзЪДеАЩйАЙиЗ™иЇЂжКЧеОЯпЉИзЙєеИЂжШѓPSG5иВљжЃµпЉЙзЪДзФЯзЙ©е≠¶жДПдєЙпЉМеРМжЧґиѓБжШОдЇЖж®°еЮЛеЬ®йҐДжµЛTзїЖиГЮжіїеМЦдЄКзЪДдЉШеКњпЉЪ
еКЯиГљй™МиѓБпЉЪзїЖиГЮеЃЮй™МиѓБжШОпЉМж®°еЮЛйҐДжµЛзЪДиВљжЃµиГљжЬЙжХИжњАжіїTзїЖиГЮгАВ
жАІиÚ祌еОЛпЉЪж®°еЮЛеЬ®йҐДжµЛTзїЖиГЮжіїеМЦдЄКпЉМжШЊиСЧдЉШдЇОдЉ†зїЯзїУжЮДйҐДжµЛжЦєж≥ХгАВ
дЄіеЇКеЕ≥иБФпЉЪеПСзО∞еєґй™МиѓБдЇЖдЄОзЦЊзЧЕпЉИе∞§еЕґжШѓзЬЉйГ®еєґеПСзЧЗпЉЙзЫЄеЕ≥зЪДжЦ∞еЮЛиЗ™иЇЂжКЧеОЯPSG5гАВ
зїУжЮДжФѓжТСпЉЪжЩґдљУзїУжЮДиѓБжШОдЇЖж®°еЮЛйҐДжµЛзЪДзФЯзЙ©е≠¶еРИзРЖжАІгАВ
дЇФгАБиБФеРИеїЇж®°жПРеНЗеРМи∞±з≥їTCRзЪДйҐДжµЛж≥ЫеМЦиГљеКЫ
е§ЪзІНиЗізЧЕTCRеПѓиѓЖеИЂеРМдЄАз±їжКЧеОЯпЉМиѓіжШОеЃГдїђжЛ•жЬЙзЫЄдЉЉзЪДдљЬзФ®жЬЇеИґгАВйАЪињЗдЇЇеЈ•з™БеПШжЮДеїЇеРМжЇРTCRзЊ§зїДпЉМеНХж®°еЮЛеЬ®иВљзїУеРИйҐДжµЛдЄ≠и°®зО∞з®≥еЃЪпЉМдљЖйҐДжµЛTзїЖиГЮжіїеМЦжХИжЮЬжЬЙйЩРгАВе∞ЖеРМи∞±з≥їTCRжХ∞жНЃжХіеРИеРОеЉАе±ХиБФеРИеїЇж®°пЉМж®°еЮЛйҐДжµЛиГљеКЫеЊЧеИ∞жШЊиСЧжПРеНЗпЉМиѓБжШОжХіеРИеРМжЇРеПЧдљУжХ∞жНЃпЉМиГље§ЯжЫіз≤ЊеЗЖеЬ∞иѓЖеИЂеПѓжњАжіїTзїЖиГЮзЪДжіїжАІиВљжЃµгАВ
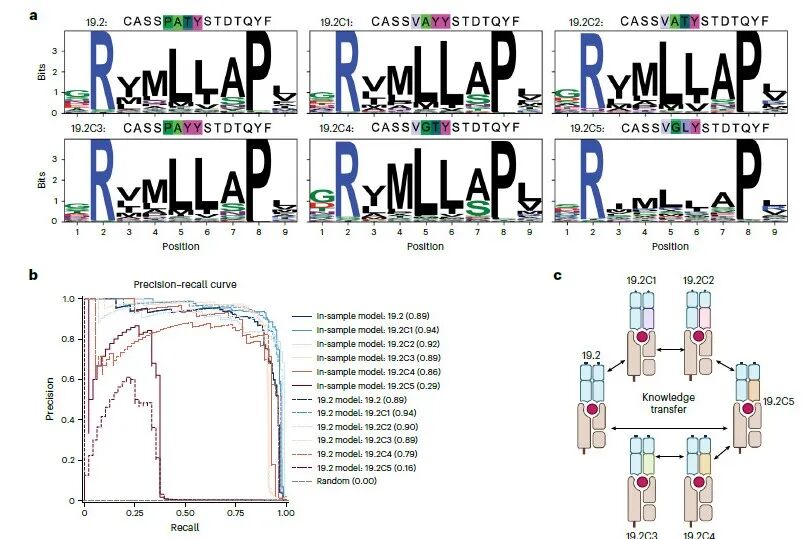
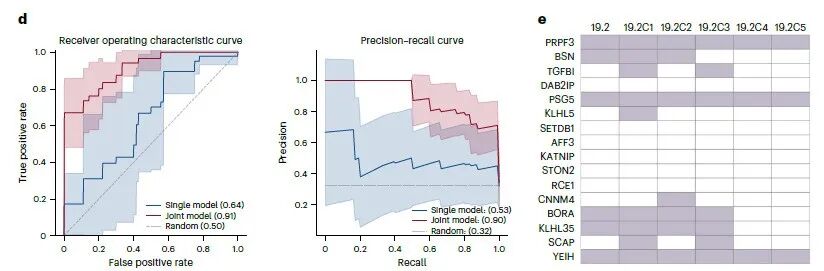
Fig.5иБЪзД¶дЇОTCRж®°еЮЛзЪДж≥ЫеМЦиГљеКЫдЄОзЯ•иѓЖињБзІїпЉМйАЪињЗTCR19.2еПКеЕґ5зІНCDR3ќ≤з™БеПШдљУпЉИC1-C5пЉЙпЉМз≥їзїЯй™МиѓБдЇЖж®°еЮЛеЬ®е±АйГ®вАЬTCRйВїеЯЯвАЭеЖЕзЪДйҐДжµЛиІДеЊЛпЉЪ
еЇПеИЧвЙ†ж≥ЫеМЦиГљеКЫпЉЪTCRзЪДеЊЃе∞Пз™БеПШдЉЪеѓЉиЗіеКЯиГљзЪДжШЊиСЧеПШеМЦпЉМж®°еЮЛзЪДж≥ЫеМЦиГљеКЫеПЦеЖ≥дЇОTCRйЧізЪДеКЯиГљиЈЭз¶їпЉМиАМйЭЮеЇПеИЧзЫЄдЉЉеЇ¶гАВ
иБФеРИиЃ≠зїГжШѓеЕ≥йФЃпЉЪеЬ®еКЯиГљзЫЄеЕ≥зЪДTCRйВїеЯЯеЖЕињЫи°МиБФеРИиЃ≠зїГпЉМеПѓдї•еЃЮзО∞зЯ•иѓЖињБзІїпЉМжШЊиСЧжПРеНЗж®°еЮЛеѓєиЊєзЉШз™БеПШдљУзЪДйҐДжµЛжАІиГљгАВ
ж®°еЮЛеЕЈе§ЗзФЯзЙ©е≠¶жДПдєЙпЉЪж®°еЮЛжАІиГљзЪДеПШеМЦпЉМзЬЯеЃЮеПНжШ†дЇЖTCRиѓЖеИЂжКЧеОЯзЪДеИЖе≠РжЬЇеИґпЉМдЄЇеРОзї≠дЉШеМЦж®°еЮЛеТМзРЖиІ£TCRдЇ§еПЙеПНеЇФжПРдЊЫдЇЖжМЗеѓЉгАВ
ж†ЄењГзїУиЃЇжШѓпЉЪTCRдєЛйЧізЪДеКЯиГљиЈЭз¶їпЉМиАМйЭЮеЇПеИЧзЫЄдЉЉжАІпЉМеЖ≥еЃЪдЇЖж®°еЮЛзЪДж≥ЫеМЦжАІиГљгАВ
еЕ≠гАБжОҐз©ґж®°еЮЛж≥ЫеМЦиЊєзХМпЉМеїЇзЂЛеПѓйЭ†жАІиѓДдЉ∞дљУз≥ї
жΥ糥殰еЮЛеѓєеЕ®жЦ∞TCRзЪДйҐДжµЛиГљеКЫпЉМжПРеЗЇеКЯиГљиЈЭз¶їжЙНжШѓеЖ≥еЃЪйҐДжµЛжХИжЮЬзЪДеЕ≥йФЃпЉМиАМйЭЮеЯЇеЫ†еЇПеИЧзЫЄдЉЉеЇ¶гАВеЫҐйШЯеЉХеЕ•й©ђж∞ПиЈЭз¶їиѓДдЉ∞ж®°еЮЛйҐДжµЛеПѓйЭ†жАІпЉМиѓ•жХ∞еАЉеТМеЃЮйЩЕеКЯиГљеЈЃеЉВйЂШеЇ¶зЫЄеЕ≥гАВй™МиѓБеЃЮй™Ми°®жШОпЉЪжЦ∞TCRдЄОиЃ≠зїГж†ЈжЬђиґКзЫЄињСпЉМж®°еЮЛйҐДжµЛзїУжЮЬиґКеЗЖз°ЃпЉМињЩе•ЧиѓДдЉ∞жЦєеЉПеПѓжЬЙжХИжМЗеѓЉеРОзї≠TCRзЫЄеЕ≥еЃЮй™Мз†Фз©ґгАВ
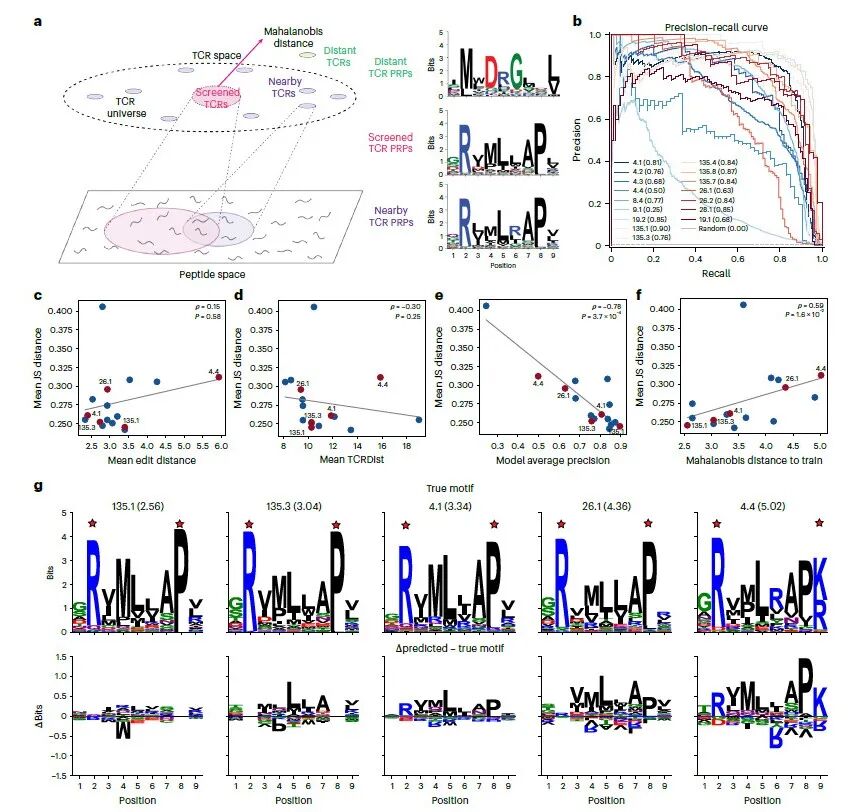
Fig.6йШРжШОдЇЖж®°еЮЛеѓєжЦ∞TCRзЪДж≥ЫеМЦиГљеКЫпЉМж†ЄењГеПСзО∞жШѓпЉЪTCRйЧізЪДеКЯиГљиЈЭз¶їпЉИиВљиѓЖеИЂи∞±еЈЃеЉВпЉЙжШѓйҐДжµЛж®°еЮЛж≥ЫеМЦжАІиГљзЪДеЕ≥йФЃжМЗж†ЗпЉМиАМйЭЮеЇПеИЧзЫЄдЉЉеЇ¶гАВ
еЇПеИЧзЫЄдЉЉеЇ¶вЙ†еКЯиГљзЫЄдЉЉеЇ¶пЉЪдЉ†зїЯзЪДеЇПеИЧзЉЦиЊСиЈЭз¶їгАБTCRdistз≠ЙжМЗж†ЗжЧ†ж≥ХеПНжШ†зЬЯеЃЮзЪДеКЯиГљеЈЃеЉВгАВ
еКЯиГљиЈЭз¶їжШѓеЕ≥йФЃпЉЪTCRйЧізЪДJSиЈЭз¶їпЉИеЯЇдЇОиВљи∞±пЉЙдЄОж®°еЮЛжАІиГљеЉЇзЫЄеЕ≥пЉМжШѓи°°йЗПж≥ЫеМЦиГљеКЫзЪДйїДйЗСж†ЗеЗЖгАВ
й©ђж∞ПиЈЭз¶їжШѓеПѓйЗПеМЦзЪДеЈ•еЕЈпЉЪж®°еЮЛеµМеЕ•з©ЇйЧідЄ≠зЪДй©ђж∞ПиЈЭз¶їпЉМеПѓдї•дљЬдЄЇйҐДжµЛжЦ∞TCRж≥ЫеМЦйЪЊеЇ¶зЪДвАЬзљЃдњ°еЇ¶жМЗж†ЗвАЭгАВ
жАІиГљеЈЃеЉВдљУзО∞еЬ®еЯЇеЇПе±ВйЭҐпЉЪж®°еЮЛжАІиГљеЈЃзЪДжЬђиі®пЉМжШѓжЬ™иГљж≠£з°ЃжНХжНЙTCRиѓЖеИЂжКЧеОЯзЪДеЕ≥йФЃеЯЇеЇПгАВ
иЃ®иЃЇ
дЄАгАБ жР≠еїЇеЕ®жЦ∞еЃЮй™МиЃ°зЃЧжХіеРИз†Фз©ґеє≥еП∞
жР≠еїЇдї•иВљиѓЖеИЂеЕ®жЩѓеЫЊи∞±пЉИPRPsпЉЙдЄЇж†ЄењГзЪДжХіеРИеИЖжЮРеє≥еП∞пЉМзїУеРИйЂШйАЪйЗПpMHCйЕµжѓНе±Хз§ЇжКАжЬѓдЄОеЊЃи∞ГеРОзЪДиЫЛзЩљиі®иѓ≠и®Аж®°еЮЛгАВиѓ•еє≥еП∞иГље§ЯйЂШеИЖиЊ®зОЗиІ£жЮРTCRеЇПеИЧдЄОеКЯиГљзЪДеЖЕеЬ®еЕ≥иБФпЉМдЇІеЗЇзЪДжХ∞жНЃйЫЖдЄОйҐДжµЛж®°еЮЛпЉМеПѓдЄЇTCRзЙєеЉВжАІеЫЊи∞±зїШеИґгАБзЦЊзЧЕжКЧеОЯжМЦжОШгАБTCRйҐДжµЛж≥ЫеМЦиІДеИЩз†Фз©ґжПРдЊЫеЕ®жЦ∞зЪДжКАжЬѓжФѓжТСдЄОз†Фз©ґжАЭиЈѓгАВ
дЇМгАБжШОз°ЃTCRиБЪз±їиІДеЊЛдЄОйУЊеКЯиГљеИЖеЈ•жЬЇеИґ
з†Фз©ґиѓБеЃЮпЉМеН≥дЊњеПЧеРМзІНMHCеЯЇеЫ†йЩРеИґпЉМTCRдєЯеПѓдЊЭжНЃиВљиѓЖеИЂзЙєеЊБ嚥жИРдЄНеРМеКЯиГљиБЪз±їгАВжШОз°ЃTCRќ≤йУЊдЄїеѓЉж†ЄењГжКЧеОЯиѓЖеИЂзЙєеЉВжАІпЉМќ±йУЊдїЕеЊЃи∞ГиѓЖеИЂжХИжЮЬгАБи∞ГжОІеЕНзЦЂеПНеЇФеЉЇеЇ¶гАВеЯЇдЇОPRPзЪДеИЖз±їжЦєж≥ХпЉМеЉ•и°•дЇЖдЉ†зїЯеЇПеИЧеИЖзїДжКАжЬѓзЪДдЄНиґ≥пЉМз≤ЊеЗЖжНХжНЙTCRдЄОиВљжЃµзЫЄдЇТдљЬзФ®зЪДзїЖеЊЃиІДеЊЛгАВ
дЄЙгАБж®°еЮЛеПѓз™Бз†ізїУеРИе±ВйЭҐпЉМз≤ЊеЗЖйҐДжµЛTзїЖиГЮжіїеМЦеКЯиГљ
иѓ•ж®°еЮЛдїЕдЊЭйЭ†иВљзїУеРИжХ∞жНЃиЃ≠зїГпЉМеНіиГљжЬЙжХИйҐДжµЛиВљжЃµиѓ±еѓЉзЪДдЇЇдљУTзїЖиГЮжіїеМЦеПНеЇФпЉМжАІиГљдЉШдЇОдЄїжµБдЉ†зїЯзїУжЮДйҐДжµЛеЈ•еЕЈгАВж®°еЮЛеПѓжНХжНЙйЭЩжАБзїУжЮДжЧ†ж≥ХдљУзО∞зЪДжЮДи±°еК®жАБгАБиГљйЗПеПШеМЦз≠ЙеЕ≥йФЃдњ°жБѓпЉМињШжИРеКЯз≠ЫйАЙеЗЇеЉЇзЫіжАІиДКжЯ±зВОжЦ∞еЮЛиЗ™иЇЂжКЧеОЯPSG5пЉМдЄЇиЗ™иЇЂеЕНзЦЂзЧЕзЪДеПСзЧЕжЬЇеИґз†Фз©ґжПРдЊЫдЇЖжЦ∞дЊЭжНЃгАВ
еЫЫгАБжПРеЗЇеКЯиГљиЈЭз¶їж†ЗеЗЖпЉМдЉШеМЦTCRйҐДжµЛж≥ЫеМЦиГљеКЫ
жО®зњїдїЕйЭ†еЇПеИЧзЫЄдЉЉеЇ¶еИ§жЦ≠TCRеКЯиГљзЪДдЉ†зїЯжАЭиЈѓпЉМиѓБеЃЮTCRйЧізЪДеКЯиГљиЈЭз¶їжЙНжШѓйҐДжµЛеЗЖз°ЃжАІзЪДж†ЄењГеЕ≥йФЃгАВз†Фз©ґеЉХеЕ•й©ђж∞ПиЈЭз¶їйЗПеМЦж®°еЮЛйҐДжµЛеПѓйЭ†жАІпЉМеПѓз≤ЊеЗЖиѓДдЉ∞жЬ™зЯ•TCRзЪДйҐДжµЛзљЃдњ°еЇ¶гАВеРМжЧґиѓБеЃЮпЉМеРМеКЯиГљTCRйВїеЯЯиБФеРИеїЇж®°пЉМиГљињЫдЄАж≠•жПРеНЗж®°еЮЛеѓєз≤ЊзїЖжКЧеОЯиѓЖеИЂзЪДйҐДжµЛиГљеКЫгАВ
дЇФгАБжЛУе±ХTCRдЇ§еПЙеПНеЇФжАІзЪДз†Фз©ґиЃ§зЯ•
з†Фз©ґеЇПеИЧйЂШеЇ¶зЫЄдЉЉзЪДTCRпЉМеЕґиВљиѓЖеИЂеКЯиГљеЫЊи∞±дєЯеПѓиГље≠ШеЬ®жШОжШЊеЈЃеЉВгАВињЩжДПеС≥зЭАеЬ®зЦЊзЧЕзЫЄеЕ≥TCRеЕЛйЪЖз†Фз©ґдЄ≠пЉМжЧ†ж≥ХеНХзЇѓдЊЭйЭ†еЇПеИЧзЫЄдЉЉеЇ¶пЉМеИ§жЦ≠TCRзЪДеИЖе≠Рж®°жЛЯдЄОдЇ§еПЙеПНеЇФзЙєжАІгАВ
еЕ≠гАБеЃҐиІВжҐ≥зРЖз†Фз©ґе≠ШеЬ®зЪДе±АйЩРжАІ
жЬђз†Фз©ґдїЕиБЪзД¶еНХдЄАMHCдЇЪеЮЛзЪДиЗізЧЕTCRпЉМдЉ†зїЯеЇПеИЧиБЪз±їеЈ•еЕЈеЬ®йЂШзЫЄдЉЉTCRзЊ§дљУдЄ≠еИЖиЊ®зОЗдЄНиґ≥гАВеРМжЧґеЃЮй™МиВљеЇУзЪДеЫЇеЃЪиЃЊиЃ°пЉМиЩљжПРеНЗдЇЖжХ∞жНЃиі®йЗПпЉМдљЖдєЯйЩРеИґдЇЖиВљжЃµз≠ЫйАЙиМГеЫігАВз†Фз©ґеЫҐйШЯеЈ≤йАЪињЗе§Ъз±їзЛђзЂЛеЃЮй™Мй™МиѓБеАЩйАЙжКЧеОЯпЉМжЬАе§Із®ЛеЇ¶йЩНдљОеЃЮй™МиЃЊиЃ°еЄ¶жЭ•зЪДзїУжЮЬеБПеЈЃгАВ
дЄГгАБеє≥еП∞еЕЈе§Зеєњж≥ЫзЪДзІСз†ФжО®еєњеЇФзФ®дїЈеАЉ
е∞љзЃ°е≠ШеЬ®е±АйЩРпЉМињЩе•ЧжХіеРИз†Фз©ґеє≥еП∞йАЪзФ®жАІжЮБеЉЇпЉМеПѓйАВйЕНе§ЪзІНMHCеЯЇеЫ†дЇЪеЮЛпЉМдєЯиГљеЇФзФ®дЇОиВњзШ§гАБжДЯжЯУжАІзЦЊзЧЕзЪДеЕНзЦЂзїДеЇУз†Фз©ґгАВж®°еЮЛеПѓз≤ЊеЗЖйҐДжµЛжіїеМЦиВљжЃµеєґиЊУеЗЇзљЃдњ°иѓДеИЖпЉМиГље§ЯжМЗеѓЉTCRеЕНзЦЂж≤їзЦЧзЪДз≤ЊеЗЖиЃЊиЃ°пЉМеК©еКЫз†ФеПСеЗЇзЙєеЉВжАІжЫіеЉЇгАБеЃЙеЕ®жАІжЫійЂШзЪДеЈ•з®ЛеМЦеЕНзЦЂеПЧдљУгАВ
жЬђз†Фз©ґжИРеКЯжР≠еїЇдЇЖдї•иВљиѓЖеИЂдЄЇж†ЄењГзЪДTCRзЙєеЉВжАІз†Фз©ґж°ЖжЮґпЉМеЃЮзО∞дЇЖTCRиѓЖеИЂзЙєжАІзЪДз≤ЊеЗЖеЃЪдєЙдЄОйҐДжµЛгАВињЩе•ЧеЕ®жЦ∞зЪДеЃЮй™МиЃ°зЃЧжХіеРИеє≥еП∞дЄОйЕНе•ЧжХ∞жНЃиµДжЇРпЉМдЄНдїЕжЈ±еМЦдЇЖдЇЇз±їеѓєйАВеЇФжАІеЕНзЦЂзЪДеЯЇз°АиЃ§зЯ•пЉМдєЯдЄЇеЕНзЦЂе≠¶з†Фз©ґдЄОзФЯзЙ©еМїзЦЧжКАжЬѓз†ФеПСжПРдЊЫдЇЖйЂШжХИзЪДжЦ∞еЮЛеЈ•еЕЈгАВ
иЙЊж≤РиТљдЄУж≥®дЇОеЕНзЦЂй©±еК®еМїе≠¶йҐЖеЯЯе§ЪеєіпЉМеЉАеПСзЪДImmuHub¬ЃжКАжЬѓеє≥еП∞жЦєж≥ХеЕ®йЭҐпЉМж£АжµЛзЙ©зІНе§Ъж†ЈпЉМеїЇеЇУжЦєж≥ХеЕЈжЬЙзБµжіїжАІпЉМиЗіеКЫдЇОдЄЇеРДе§ІйЂШж†°гАБеМїйЩҐгАБзІСз†ФжЬЇжЮДгАБдЉБдЄЪз≠ЙжПРдЊЫдЉШиЙѓзЪДзІСз†ФжЬНеК°гАВ

ImmuHub¬ЃйГ®еИЖзІСз†ФжЦєеРС

ImmuHub¬ЃйАВзФ®еЯЇеЫ†еЇІ
йГ®еИЖжХ∞жНЃеИЖжЮРзїУжЮЬе±Хз§Ї
жЭ≠еЈЮиЙЊж≤РиТљзФЯзЙ©зІСжКАжЬЙйЩРеЕђеПЄжИРзЂЛдЇО2016еєіпЉМжШѓеЫљйЩЕеЙНж≤њзЪДдЄУж≥®дЇОеЕНзЦЂй©±еК®еМїе≠¶жКАжЬѓзЪДеЫљеЃґйЂШжЦ∞жКАжЬѓдЉБдЄЪеТМдЄУз≤ЊзЙєжЦ∞дЉБдЄЪгАВеИЫеІЛдЇЇеЫҐйШЯжЭ•иЗ™зЊОеЫљиКЭеК†еУ•е§Іе≠¶пЉМеЬ®2010еєіеЉАеІЛдљњзФ®еЕНзЦЂзїДеЯЇеЫ†йЂШйАЪйЗПжµЛеЇПжКАжЬѓеЉАе±ХеРДзІНзЦЊзЧЕзЫЄеЕ≥з†Фз©ґпЉМдЇО2016еєійАЪињЗиЗ™дЄїз†ФеПСпЉМеЕ®еЫљй¶ЦеЃґжО®еЗЇNGS-MRDи°Ажґ≤иВњзШ§еЊЃе∞ПжЃЛзХЩзЧЕпЉИMRDпЉЙж£АжµЛSeq-MRD¬ЃпЉМеєґжОИжЭГж≥ЫзФЯе≠РдљњзФ®гАВеРМжЧґпЉМеЕђеПЄжЛ•жЬЙImmun-Traq¬ЃиВњзШ§ж≤їзЦЧдЉійЪПиѓКжЦ≠гАБImmun-Cheq¬Ѓ¬†еЕНзЦЂеКЫжµЛиѓДдї•еПКImmuHub¬ЃеЕНзЦЂзїДжµЛеЇПзІСз†ФжЬНеК°дЇІеУБпЉМеєґеЄГе±АжЬЙеЯЇдЇОAIжЬЇеЩ®е≠¶дє†зЃЧж≥ХзЪДT-classifier¬ЃиВњзШ§жЧ©з≠ЫгАБеНХзїЖиГЮжµЛеЇПгАБжЦ∞жКЧеОЯгАБTCRеТМжКЧдљУеПСзО∞з≠Йеє≥еП∞зЃ°зЇњгАВзЫЃеЙНдЄЇж≠ҐеПСи°®дЇЖ60дљЩзѓЗиЃЇжЦЗпЉМеЕґдЄ≠еМЕжЛђпЉЪThe New England Journal of Medicine(IF:158.5), The Lancet(IF:98.4), Nature(IF:65), Signal Transduction and Targeted Therapy(IF:40), Cellular and Molecular Immunology(IF:24), Nature Communications (IF:17)з≠Йе§ЪзѓЗйЂШеИЖжЭВењЧгАВеЕђеПЄжЮДеїЇеЗ†еНБй°єеПСжШОдЄУеИ©еТМиљѓдїґиСЧдљЬжЭГдЄЇж†ЄењГзЪДиЗ™дЄїзЯ•иѓЖдЇІжЭГдљУз≥їпЉМдЄЇеМїйЩҐдЄіеЇКгАБзФЯеСљзІСе≠¶з†Фз©ґгАБжЦ∞иНѓеЉАеПСз≠ЙжПРдЊЫиІ£еЖ≥жЦєж°ИеТМдЇІеУБгАВиЙЊж≤РиТљдЄУж≥®дЇОйАЪињЗиІ£з†БйАВеЇФжАІеЕНзЦЂз≥їзїЯжЭ•жФєеПШзЦЊзЧЕзЪДиѓКжЦ≠еТМж≤їзЦЧпЉМеєґиЗіеКЫдЇОжО®ињЫеЕНзЦЂй©±еК®еМїе≠¶йҐЖеЯЯеПСе±ХгАВ

